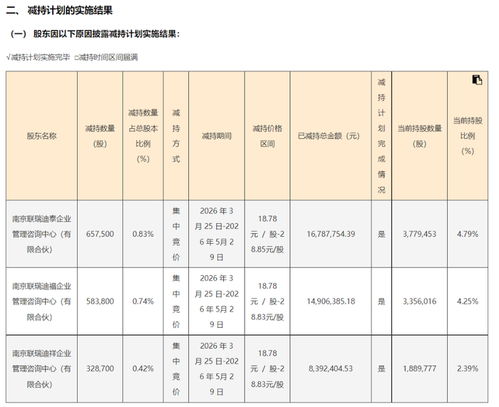
一、核心架构图览与总览
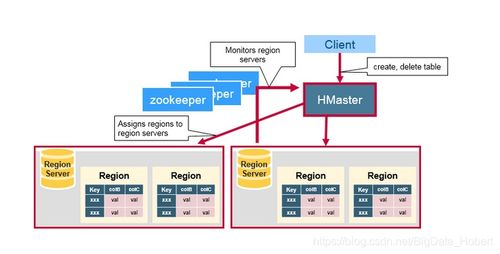
HBase是一个构建在Hadoop文件系统(HDFS)之上的分布式、可扩展的NoSQL数据库。其架构设计旨在实现海量数据的实时读写访问。一张清晰的架构图通常包含以下核心层次与组件:
- 客户端层:提供Java API、REST API、Thrift等接口,供应用程序访问。
- ZooKeeper:作为分布式协调服务,负责管理集群状态(如主HMaster选举)、元数据入口(-ROOT-和.META.表位置)以及RegionServer的心跳监控。
- HMaster:管理节点,负责表管理(创建、删除、修改)、Region分配与负载均衡、RegionServer故障转移。通常高可用部署。
- RegionServer:工作节点,负责处理数据的读写请求,管理多个Region。
- Region:数据表的分区,是负载均衡和数据分布的基本单位。一个表最初只有一个Region,随着数据增长会自动分裂。
- Store:每个Region按列族(Column Family)划分为多个Store。
- MemStore:每个Store包含一个内存写缓存,写入数据首先顺序写入HLog(WAL),然后放入MemStore,排序后批量刷新到磁盘。
- HFile:存储在HDFS上的底层数据文件,是SortedMap的持久化格式,包含索引以加速查询。
- HDFS:作为底层存储,提供数据的高可靠性和高可用性。
数据流向:写请求 -> ZooKeeper(获取元数据)-> RegionServer -> HLog(预写日志)-> MemStore -> 定期刷写为HFile存储于HDFS。读请求则可能合并MemStore和多个HFile的数据。
二、架构组件深度解析
1. HMaster:指挥官
- 职责:非数据路径节点,主要负责元数据管理和集群调度。
- 表操作:DDL语句的执行者。
- Region管理:监控RegionServer,在启动、故障或负载不均时,负责Region的分配、迁移与合并。
- 高可用:多个HMaster通过ZooKeeper选举出Active Master,备用者处于待命状态。
2. RegionServer:主力工兵
- 核心服务单元:每个节点运行一个RegionServer进程,通常与HDFS DataNode同机部署以减少数据网络传输。
- Region托管:托管多个Region,处理这些Region的所有IO请求。
- 组件构成:
- BlockCache:读缓存,采用LRU策略,缓存频繁访问的数据块。
- MemStore:写缓存,每个列族对应一个,数据在内存中按行键排序。
- HLog (WAL):预写日志,每个RegionServer一个,确保数据持久性。写操作先日志后内存,防止MemStore数据丢失。
- 刷写与压缩:定期将MemStore数据刷写(Flush)为新的HFile到HDFS;后台进程对多个小HFile进行合并压缩(Compaction),优化读取性能并清理删除标记。
3. Region与数据模型
- 数据逻辑视图:表(Table) -> 行键(RowKey) -> 列族(CF) -> 列限定符(Qualifier) -> 时间戳(Timestamp) -> 值(Value)。
- 物理存储:表按行键范围水平分割为多个Region。每个Region内,数据按列族物理存储,同一列族的所有列存储在同一个Store中。
- Region分裂:当Region大小达到阈值,会自动分裂为两个,由HMaster重新分配,实现水平扩展。
4. ZooKeeper:神经中枢
- 协调者:维护集群配置信息,实现分布式锁和选举机制。
- 关键作用:
- 存储HMaster和RegionServer的注册信息与活跃状态。
- 存储所有Region的寻址入口(-ROOT-表位置,现已简化,但元数据路径仍由其管理)。
- 监控节点故障并通知HMaster。
5. HDFS:坚实底座
- 持久化存储:所有HFile、HLog最终存储在HDFS上,享受其自动多副本(默认3份)带来的容错能力。
- 数据本地性:RegionServer尽量调度到存储其对应HFile副本的DataNode上,实现“移动计算而非数据”,提升读性能。
三、HBase在信息系统集成服务中的应用与集成指南
在构建企业级信息系统集成平台时,HBase常作为海量结构化/半结构化数据的存储与实时查询引擎。
1. 典型应用场景
- 用户画像与行为日志:存储用户的点击流、交易记录、属性标签,支持实时查询和批量分析。
- 物联网时序数据:存储设备传感器上报的带时间戳的数据,行键设计可包含设备ID与时间戳逆序。
- 消息与订单历史:存储在线系统的历史消息、订单状态变更,供查询追溯。
- 内容管理系统的元数据与索引。
2. 集成模式与最佳实践
- 数据管道集成:
- 写入端:通过Kafka等消息队列承接业务系统数据,由Spark Streaming、Flink或自定义客户端写入HBase,实现流式入库。
- 读取端:提供REST/Thrift接口服务层,封装HBase Java API,供前端或微服务调用。可使用Phoenix提供SQL化查询层。
- 与Hadoop生态集成:
- 批量分析:使用MapReduce、Spark直接读取HBase数据进行离线分析,结果可写回HBase或HDFS。
- 数据同步:通过Sqoop与关系数据库进行批量导入导出;使用Canal/Apache NiFi进行近实时同步。
- 设计要点:
- 行键设计:这是最重要的设计决策,影响数据分布和访问性能。需考虑散列性、有序性以满足扫描和热点规避需求(如加盐、哈希、反转)。
- 列族设计:不宜过多(通常1-3个),因为每个列族独立存储,跨列族的事务和扫描效率低。将访问模式相似的列放在同一列族。
- 版本与TTL:合理设置数据版本数和生存时间,实现自动过期清理。
- 预分区:提前根据行键范围创建多个Region,避免初始单Region热点和后续自动分裂带来的性能波动。
3. 运维与监控考量
- 监控体系:集成HBase原生Metrics(对接Ganglia、Prometheus)及HBase Web UI,关注Region分布均衡性、请求延迟、Compaction队列、BlockCache命中率等核心指标。
- 高可用保障:确保HMaster、ZooKeeper集群的高可用部署;规划RegionServer的滚动重启与扩容流程。
- 备份与恢复:利用HBase Snapshot进行快速元数据与数据备份,或使用Export/Import工具。
四、
HBase的架构巧妙结合了LSM-Tree的写优势和HDFS的存储可靠性,通过分层(客户端、协调层、主控层、存储层)和分片(Region)设计实现了水平扩展与高性能。在信息系统集成服务中,它扮演着大数据存储与实时服务的核心角色。成功的集成不仅需要理解其架构原理,更需在数据模型设计、访问模式匹配、生态工具链整合及运维监控上深入实践,方能构建出稳定高效的数据基石。
(注:本文旨在提供全面的架构解析与集成指引,实际部署与设计应结合具体业务需求与集群规模进行。)